| Prev | Next |
Code Analyzer
The Code Analyzer is an essential tool for anyone who deals with source code every day.
It can perform very complex queries on source code repositories at lightning speed either locally or on a Sparx Intel cloud service. The queries are composed using a high level language developed by Sparx System. The language uses a small but expressive vocabulary that is easily learned and permits code metrics to be queried much faster than conventional methods.
Access
|
Ribbon |
Develop > Source Code > Code Analyzer |
Code Analyzer Menu
The Code Analyzer menu is displayed when you click on the ![]() icon in the top-left corner of the window.
icon in the top-left corner of the window.
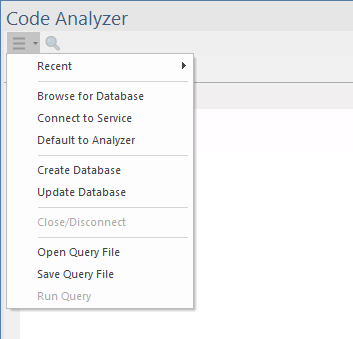
The menu provides various commands for activities associated with the use of the Code Analyzer, including such things as choosing a Code Miner database to use, updating the Code Miner database and Opening a Query File for editing.
This table describes each of the menu commands.
Command |
Description |
|---|---|
|
Recent |
Displays a sub-menu that provides a list of recent connections to services and local database files. |
|
Browse for Database |
Displays a 'file chooser' dialog, allowing you to browse for a Code Miner database on your machine. |
|
Connect to Service |
Displays the 'Code Miner Database Connection' dialog, in which you specify connection details for a (list of) Code Miner Database services. |
|
Default to Analyzer |
Selecting this option results in the Code Analyzer automatically connecting to the Code Miner service configured for the active Execution Analyzer Script, when the Code Analyzer is started. |
|
Create Database |
Displays the 'Create Code Miner Database' dialog, which allows you to create a Code Miner database from a source code repository in the file system. |
|
Update Database |
Displays the 'Code Miner Database Update' dialog, which allows you to perform an incremental update to an existing Code Miner database, to incorporate recent changes to source code files. |
|
Close/Disconnect |
Closes or disconnects from the Code Miner Database library or service. |
|
Open Query File |
Shows a 'file open' dialog allowing you to choose an mFQL query file from the file system. |
|
Save Query File |
Shows a 'file save' dialog allowing you to save the current mFQL query to a named file. |
|
Run Query |
Runs the entire query or selected contents of the query entered in the 'Query' tab editor. Shortcut . |
Before Using the Analyzer
Before you can use the Code Analyzer, you must first create a Code Miner database or locate an existing one that the Code Analyzer can access. Creating a Code Miner database is summarized here, or you can read a detailed description in the Help topic Creating a New Code Miner Database.
Depending on the location of the library you will be using, you should either:
- Select a Code Miner library file to use, or
- Connect to a service that is hosting a Code Miner database.
Once you have completed these steps, you are ready to begin writing and running queries in the Code Analyzer.
Creating a Code Miner Database
Code Miner databases are built from source code repositories. The process is similar to code compilation, using the language grammar to analyze individual files.
There are two types of build - full and incremental. The initial full build might take some time, but the subsequent incremental builds are incredibly quick.
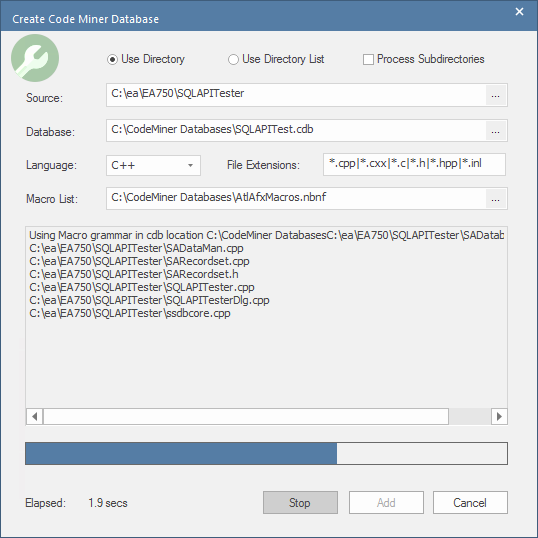
Using a Directory as input
You can select a single folder as the root of the source code you want to compile. With this option you can choose to include subdirectories
Using a Directory List
Sometimes, you want to use more than a single project, but not all the projects are under a single directory. In this case, you can create a text file that lists the full path to each folder you want to include and you specify that text file in the 'Source' field. Each directory path should be listed on a separate line.
c:\myprojects\project1\tools\scintilla
c:\myprojects\project2\src
d:\mylibs\lib1\src
If you want to recursively process the sub-directories within a directory, precede the path with an exclamation mark like this:
!d:\mylibs\lib1\src
Any line that begins with a # character is treated as a comment.
# include scintilla
c:\myprojects\project1\tools\scintilla
Language
In this field, you specify the language used in the source code from which this Code Miner database is being built.
Available languages are: C++, C#, Java, XML, MDGTechnology and Custom.
Macro List
When the language selected is 'C++', the 'Macro List' selection field is displayed . For C++, the success and depth of information compiled into the database can be inextricably linked to the use of macros. This field can be used to select an nBNF macro file that will be used as an auxiliary grammar component for the compilation.
By default the macro file will default to the macro file in the Enterprise Architect installation folder. You are free to modify or extend the content of this file to suit your requirements - for example, when you need to correct errors reported in the compilation log file.
Grammar
Sparx Systems has developed grammars for all of the languages listed in the drop-down selection list; C++, C#, Java, XML and also MDGTechnology. For these languages a built-in grammar file is used.
There is also an option to select a 'Custom' language. When 'Custom' is selected, the 'Grammar' field is displayed. This field is used to specify a file containing the grammar for your custom language. The Code Miner will then use that grammar to parse the source code written in that language.
Users that develop a Custom language, will need to specify grammar rules for that language and save them into an nBNF file. Enterprise Architect's Grammar Editor is designed specifically for that purpose.
The Help Topic Grammar Framework provides detailed information on writing an nBNF grammar.
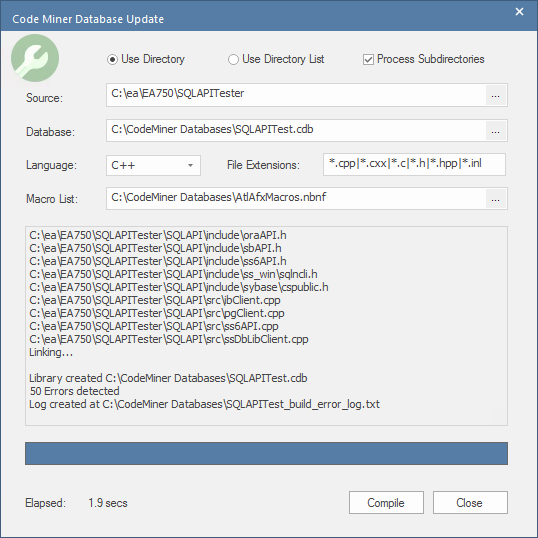
Updating a Code Miner Database
From time to time, you will want to update your Code Miner database. Typically, when you have made changes to your source code, but also after updating a grammar file or extending a macro file.
The process to update a database is very similar to creating a new database, but faster because you are not starting from scratch. Simply choose the menu option 'Update Database'. The 'Code Miner Database Update' dialog will display. The input fields will be populated with values from the last build. Proceed as for 'Creating a Code Miner Database'.
Selecting a Code Miner Database File
If you choose to use a library file for your Code Miner database, choose the menu option 'Browse for Database'. This will display a 'File Chooser', where you can browse for and select a *.cdb file.
Connecting to a Service
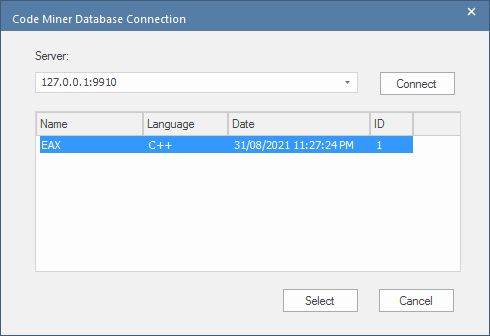
When connecting to a service, the dialog lists all databases hosted by the service.
You can choose to select an individual database in the list, or simply click the , in which case queries will be executed across all databases listed by the service.
Running Queries
Once you have connected to a Code Miner database, you are ready to start running queries.
To run a query, select the Query tab in the Code Analyzer window, type in your query, then click on the ![]() icon to execute the query.
icon to execute the query.
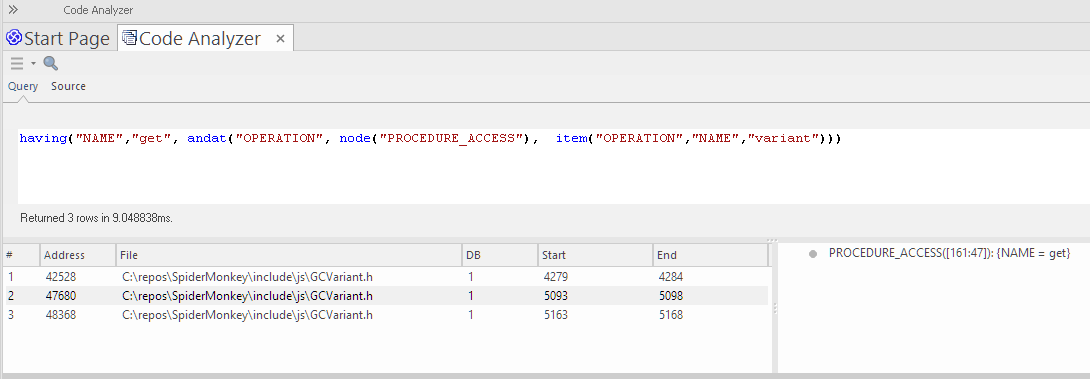
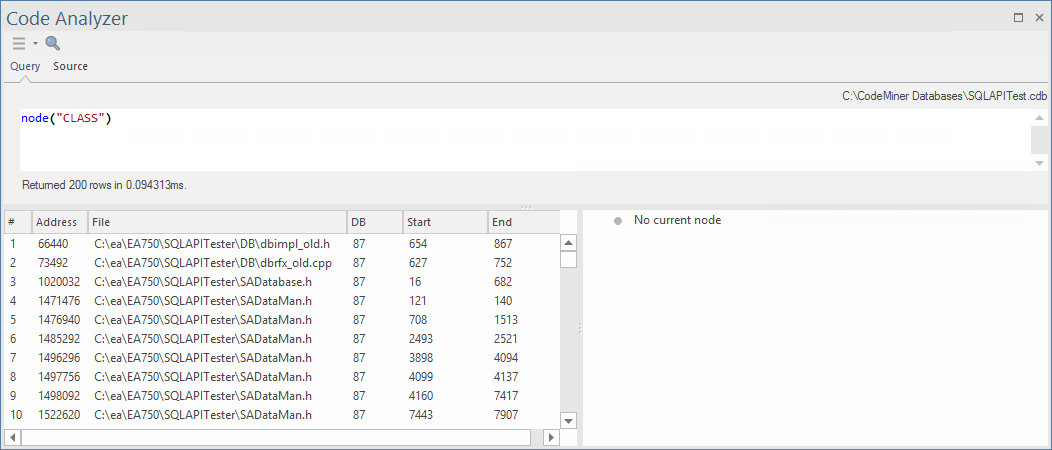
In this example, we have run a simple query node("CLASS"), which will return all 'Class' nodes found in the Code Miner database.
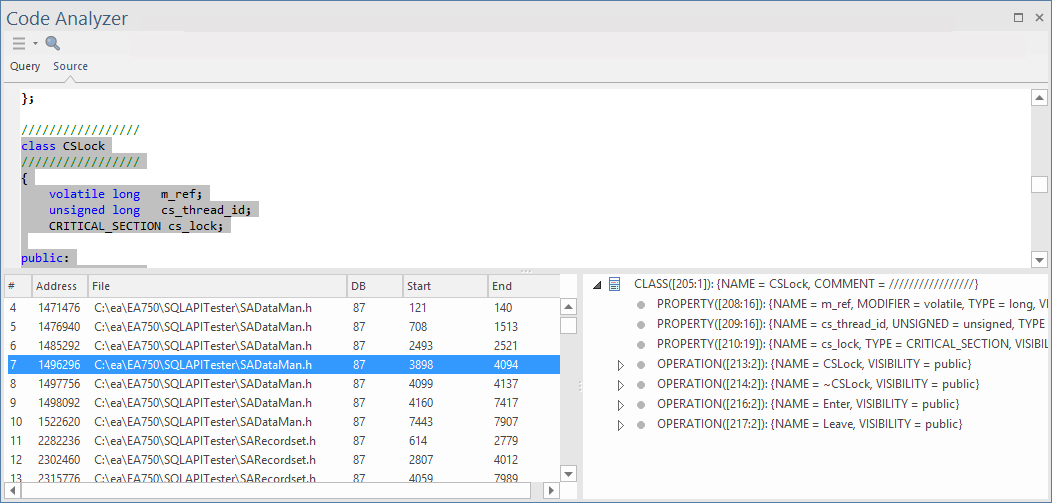
By selecting a result in the lower-left panel, the 'Source' tab is activated and displays the source code corresponding to the selected node. Details for that class node are displayed in the lower-right panel.
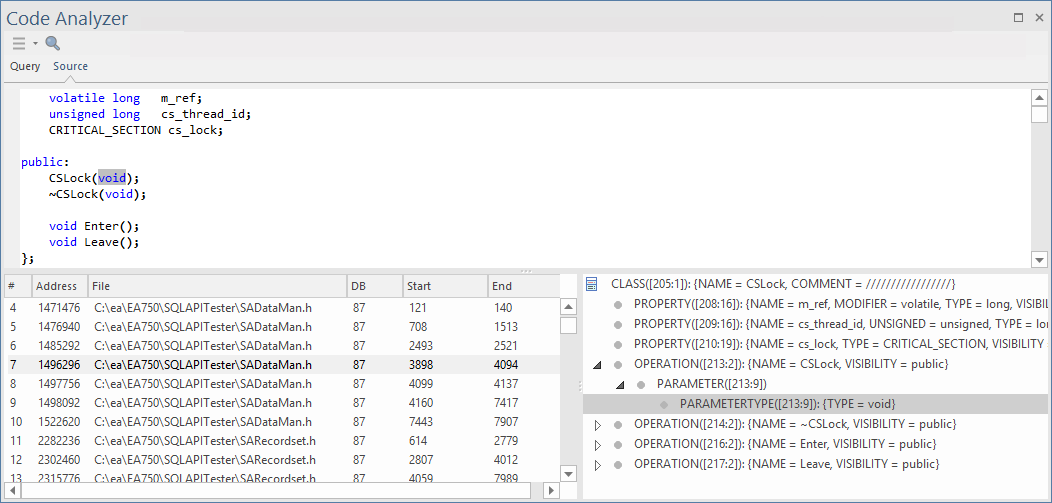
Selecting a detail item in the lower-right panel, results in narrowing the selection within the source code, as shown here.
Query Example - Intersection
As an example, this mFQL query finds all the classes that have an operation named GetOption.andat( "CLASS", item("OPERATION", "NAME", "GetOption"), node("CLASS"))
This clause returns a set of operations for which the 'NAME' value is "GetOption":
item("OPERATION", "NAME", "GetOption")
This clause returns a set of all Class nodes:
node("CLASS")
Formal syntax:
andat( string:rule, set:left, set:right)
'andat' takes the set of operations (left), applies the rule "CLASS" (only include rows that have a CLASS parent), then intersects that set with the set of all known classes (right). If the intersection succeeds, the operation node is added to the result set, otherwise it is excluded.
The Query Language - mFQL
The query language used with the Code Analyzer is described in full, in the Code Miner Query Language (mFQL) Help topic.
A brief description and some examples are also presented here.
The mFQL language is based on sets. Each statement works using the various types of set operations of which there are only a few.
Learn More
- Code Miner Framework
- Code Miner Libraries
- Code Miner Queries
- Code Miner Query Language (mFQL)
- Sparx Intel Service
- Analyzer Scripts - Execution Analyzer
- Code Miner Script - Execution Analyzer