| Prev | Next |
Creating a New Code Miner Database
Enterprise Architect's Code Analyzer, the Intelli-sense features of its code editors and it's search tools all make use of Code Miner Databases.
A Code Miner Database is created by parsing source code files according to grammar rules for the selected language and storing the resulting Abstract Syntax Tree, in a read-optimized database. One or more databases can be combined to form a Code Miner Library.
Access
|
Code Analyzer window |
From the Code Analyzer window, click on the menu button, |
|
Execution Analyzer Script Editor |
With the Execution Analyzer's Script Editor window open, select the page 'Code Miner > Libraries', then click on the 'Create' button. |
Create Code Miner Database Dialog
The 'Create Code Miner Database' dialog is used to initiate the process of parsing source code files to create a Code Miner database. On the dialog, you specify a range of inputs used by the process, such as Source Code folder, Language and Macro List file, as well as the output filename. The dialog fields are described in the table presented below.
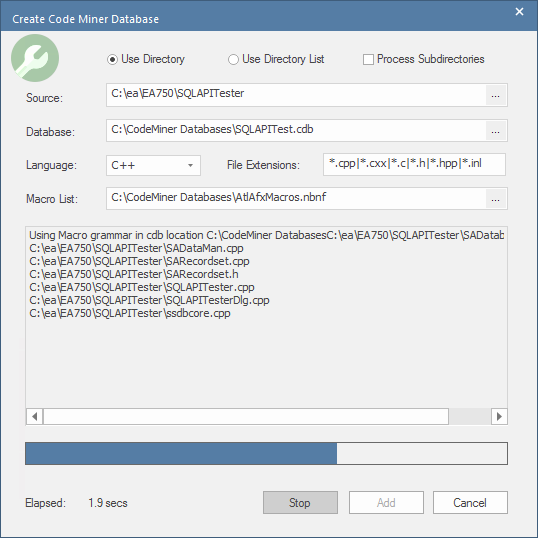
Field |
Description |
See also |
|---|---|---|
|
Use Directory |
Select this option when all of the source files to be processed reside under one directory. When this option is selected, the checkbox 'Process Subdirectories' is enabled. |
|
|
Use Directory List |
Select this option when your project source code resides in multiple separate directories. In this case, you use the 'Source' field to specify a file that contains a list of directories containing the source code to be processed. |
|
|
Process Subdirectories |
This check-box is enabled when the 'Use Directory' option is selected. When selected, source code file residing within any subdirectories of the specified 'Source' directory will also be processed. |
|
|
Source |
This field is used to specify the directory (or directories) containing source code files that will be processed to create the Code Miner database. When the option 'Use Directory' is selected, this field is used to specify the root folder in which to search for source code files. When the option 'Use Directory List' is selected, this field is used to specify a user created file containing a list of path names to the directories that contain the source files to be processed. Clicking the |
|
|
Database |
This field specifies the full path name of the Code Miner database file that will be created. The filename extension '.cdb' is used for this file. |
|
|
Language |
This is a drop-down list, where you specify the language used in the source code files being processed. There are a number of languages for which Enterprise Architect provides 'built-in' support. (There are built-in grammars used for parsing the supported languages). There is also an option to choose a 'Custom' language. If you choose to use a custom language, you will need to create your own grammar to support parsing of that language. When the 'Custom' option is selected, the field 'Grammar File' will be displayed, allowing you to specify the file that defines your custom grammar. |
|
|
File Extensions |
This field lists a number of filename extensions that are typically associated with source code files of the chosen language. Only files with filename extensions matching those in the list will be processed by the parser. You can add or remove filename extensions to suit your needs. |
|
|
Macro List |
When the language selected is 'C++', the 'Macro List' selection field is displayed. The Macro List field lets you specify a file that provides a list of macros that the parser should skip when it encounters them. For the C++ language, macros present a problem to the parser because they hide native language constructs. Adding the name of a macro to the Macro List file and updating the database will usually clear all the errors related to that macro. For more information, see the section Extending the Macro List File below. |
|
|
Grammar File |
Sparx Systems has developed grammars for all of the languages listed in the drop-down selection list. C++, C#, Java, XML and also MDGTechnology. There is also an option to select a 'Custom' language. Users that develop a Custom language, will need to specify grammar rules for that language and save them into an nBNF file, so that the Code Miner can correctly parse source code written in that language. Enterprise Architect's Grammar Editor is designed specifically for that purpose. When you select "Custom" as the language, you should then specify the grammar file you created for that language, so that the Code Miner can correctly parse your source code. The Help Topic Grammar Framework provides detailed information on writing an nBNF grammar. |
Grammar Framework |
|
Output Window |
The output window shows the progress of parsing the source code files. Upon completion, it also shows the names of the database file and the log file that were created along with the number of errors encountered. |
|
|
Compile/Stop button |
The 'Compile' button is used to start the processing operation. This button changes to a 'Stop' button once processing begins, allowing the user to abort the operation. |
|
|
Add button |
Once a database has been compiled, the 'Add' button can be used to add that database to a Code Miner Library. Multiple databases can be added together to build up a library that covers many source code projects. Note: When the 'Create Code Miner Database' dialog is opened from the Code Analyzer window, the 'Add' button is not displayed. |
 button opens a 'File Chooser' dialog, that allows you to browse for and choose a file with the extension '.ssdirlist'. For more information, see the section Directory List File below.
button opens a 'File Chooser' dialog, that allows you to browse for and choose a file with the extension '.ssdirlist'. For more information, see the section Directory List File below.Directory List File
If you choose to specify a Directory List file, you will need to create a simple text file using the filename extension '.ssdirlist', that lists the full path to each directory you wish to process, with one path per line. For example:
c:\myprojects\project1\tools\scintilla
c:\myprojects\project2\src
d:\mylibs\lib1\src
If you wish to recursively process the subdirectories within a listed directory, precede that path with an exclamation mark like this:
!d:\mylibs\lib1\src
Any line that begins with a # character is treated as a comment:
# include scintilla
c:\myprojects\project1\tools\scintilla
Extending the Macro List File
For the C++ language, macros present a problem for grammars because they hide native language constructs. The parser cannot not perform substitution on macros as they are often defined conditionally and the parser has no idea about the architecture. The Macro List file provides a list of macros that the parser should skip when it encounters them.
When you build a Code Miner database for a C++ source code repository, you might see errors listed. When an error occurs, use the error log to find and inspect the line of code that caused the error. This almost always identifies a macro that is causing the grammar failure. Adding that name to the macro list and updating the database will usually clear all the errors related to that macro.
For example, the error log shows this error:
C:\ea\EA750\SQLAPITester\SQLAPI\include\asa\sqlfuncs.h, line:12, col:18, Unexpected symbol ','.
Upon inspection, the line of code causing the error is this:
FUNC_INFO( extern, void, _esqlentry_, sqlstop, (SQLCA *))
(There are also many other similar lines using the macro 'FUNC_INFO'.)
So, we edit the default Macro List file, 'AtxAflMacros.nbnf', adding this line:
"FUNC_INFO" "(" skipBalanced("(", ")") ")" |
This line instructs the parser, upon encountering the macro "FUNC_INFO", to apply the function skipBalanced("(", ")"), which takes two parameters; in this case they are the opening and closing parentheses. So, the parser is instructed to ignore everything in between the opening and closing parentheses.
When the change to the Macro List file is saved and the database is recompiled (updated), all of the errors pertaining to the macro "FUNC_INFO" have been eliminated.