| Prev | Next |
Reference Overview
Reference data is an important part of a repository and, apart from ensuring integrity and consistency, can drive the visualizations of reports and dashboard widgets. You can, for example, visualize the Requirements grouped by Status and Difficulty using Charts and graphs. You can define reference data by using the dialogs for each reference data type or by importing it from another repository. It is best practice to set up the metadata before populating the repository with your organization's modeling information. This ensures that when you add elements you will have the right information available, and removes the need to change the elements again.
There are different types of reference data, some of which apply at a repository level - such as Status Codes and Authors - and some that are more technical in nature - such as Code Engineering and Database Datatypes - that apply to particular element or tool types.
You can transfer reference data between repositories by exporting it from one repository and importing it into another; this mechanism can save time and ensure consistency between repositories.

Settings ribbon Reference Data panel.
- UML Types - Stereotypes, Tagged Value Types and Cardinality Values
- People - Authors
- General Types - Status Types, Constraints, Requirement Types
- Project Indicators - Risk, Metric, Effort
- Estimation Factors - Technical and Environmental
- Datatypes and Namespaces
- People
- General Types
UML Types
These are part of the UML Grammar and allow you to extend the core language to make it more suitable for your organization's projects. You use them to create new types (Stereotypes) that are relevant to the industry you work in or to add specific properties (Tagged Values) that help to specify the important aspects of elements of our domain. You can also specify a set of number pairs that specify how many (Cardinalities) of one item relates to another item.
People
People are the stakeholders who participate in some way in the modeling of the enterprise and its projects. They include the people who create and maintain the models (Authors), the parts they play in the modeling effort (Roles), the people who carry out project related tasks (Resources) and the people who ultimately requisitioned the models and system (Clients).
General Types
These are collections of meta data values that you use in drop-down lists when defining element properties. They add rigor to your models and are also used extensively in creating visualizations.
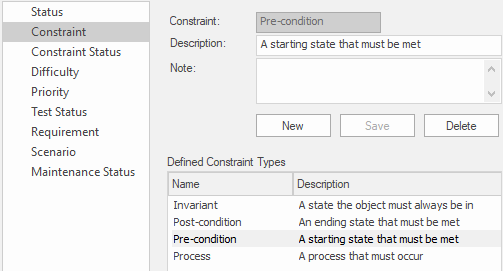
Constraints Type node of the General Types window showing the Pre Condition type.
Project Indicators
You can add a new type to the global set of risk types.
Maintenance
You can define Risk type and Test types which can be used when creating project based Risks and Test Respectively. There are a set of predefined types but you can add new types or modify or delete existing ones.
Metrics and Estimation
You can estimate the size of a software centric system by using Use Case points which utilize Environment and Technical Complexity factors and an hourly rate to calculate the effort required.
Auto Names and Counters
You can set a predefined name prefix including a counter for all element types which is used whenever a new element is created incrementing the counter each time.
Data Types and Namespaces
These define the set of data types used by both programming languages and database systems. These are preset for each of the languages and systems but you can define new types as required. You can also add completely new products that are not part of the predefined set and add types to these. Namespaces can also be defined.
Sharing Reference Data
Enterprise Architect pre-populates reference data as default data, which you can then edit as required. Another productive way of getting data into a repository is to import it from an existing Enterprise Architect repository. This is a simple process of exporting the data from one repository and importing it into another.